SmallThinker (AI): Family of Efficient LLMs Trained for Local Deployment
The generative AI landscape is dominated by massive language models, often designed for the vast capacities of cloud data centers. These models, while powerful, make it difficult or impossible for everyday users to deploy advanced AI privately and efficiently on local devices like laptops, smartphones, or embedded systems. Instead of compressing cloud-scale models for the edge—often resulting in substantial performance compromises—the team behind SmallThinker asked a more fundamental question: What if a language model were architected from the start for local constraints?
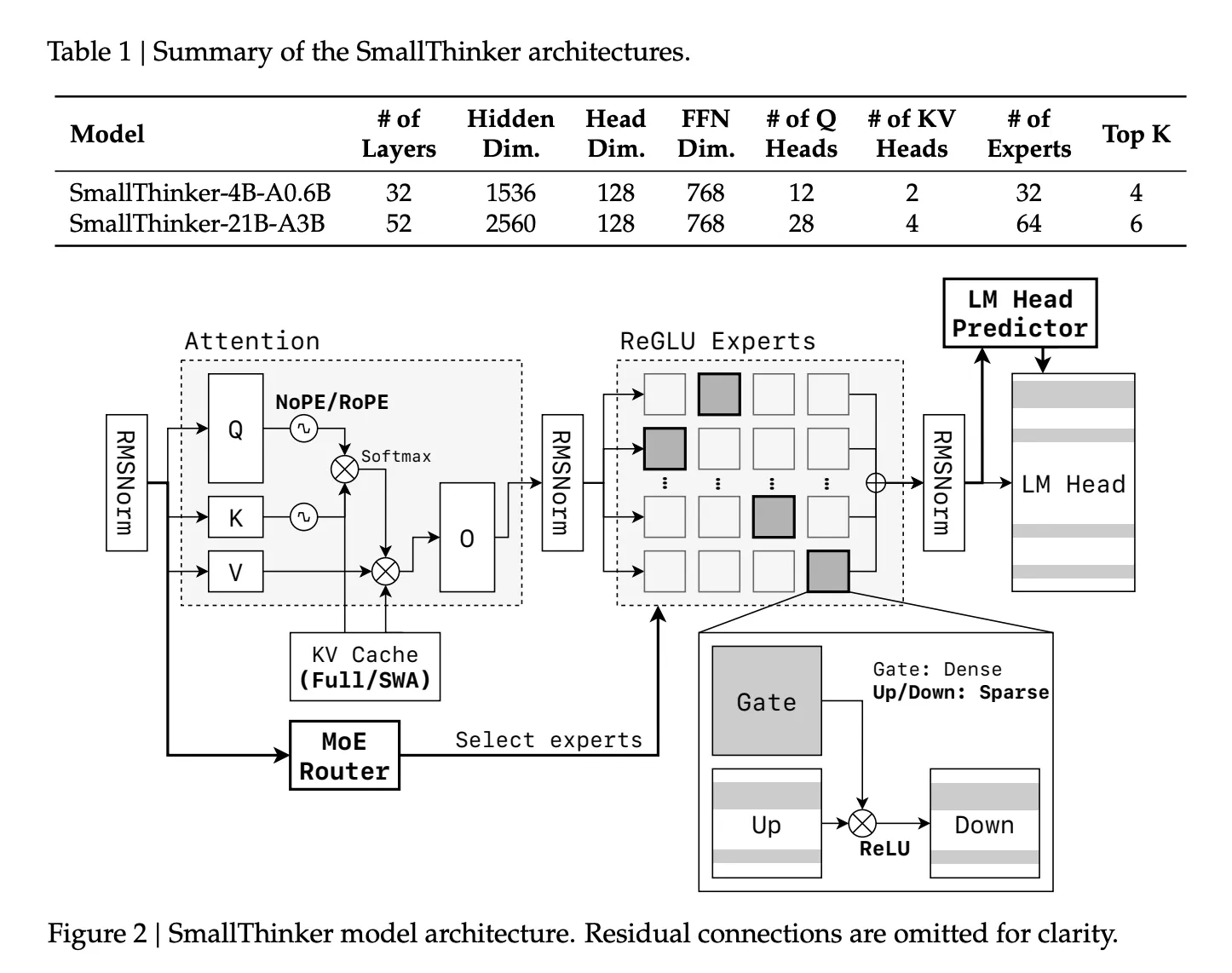
This was the genesis for SmallThinker, a family of Mixture-of-Experts (MoE) models developed by Researchers at Shanghai Jiao Tong University and Zenergize AI, that targets high-performance, memory-limited, and compute-constrained on-device inference. With two main variants—SmallThinker-4B-A0.6B and SmallThinker-21B-A3B—they set a new benchmark for efficient, accessible AI.
#Local Constraints Become Design Principles
Architectural Innovations
Fine-Grained Mixture-of-Experts (MoE): Unlike typical monolithic LLMs, SmallThinker's backbone features a fine-grained MoE design. Multiple specialized expert networks are trained, but only a small subset is activated for each input token.
This approach offers several advantages:
- Reduced Active Parameters: While the total parameter count may be 4B or 21B, only a fraction (0.6B or 3B) is active during inference
- Memory Efficiency: Inactive experts don't consume GPU/CPU memory during processing
- Computational Savings: Fewer active parameters mean less computation per token
- Specialized Knowledge: Each expert can focus on specific domains or linguistic patterns
Training Methodology
SmallThinker models were trained using a novel approach that prioritizes efficiency from the ground up:
- Native Small-Scale Training: Rather than distilling from larger models, SmallThinker was trained directly at its target size
- Balanced Expert Utilization: Special attention was paid to preventing "expert collapse" where only a few experts get used
- Optimized for CPU and Mobile GPUs: Training objectives included performance metrics on consumer hardware
- Instruction Tuning: Fine-tuned on carefully curated instruction datasets to maximize helpfulness while minimizing resource usage
#Performance Benchmarks
The SmallThinker models demonstrate impressive capabilities despite their efficient design:
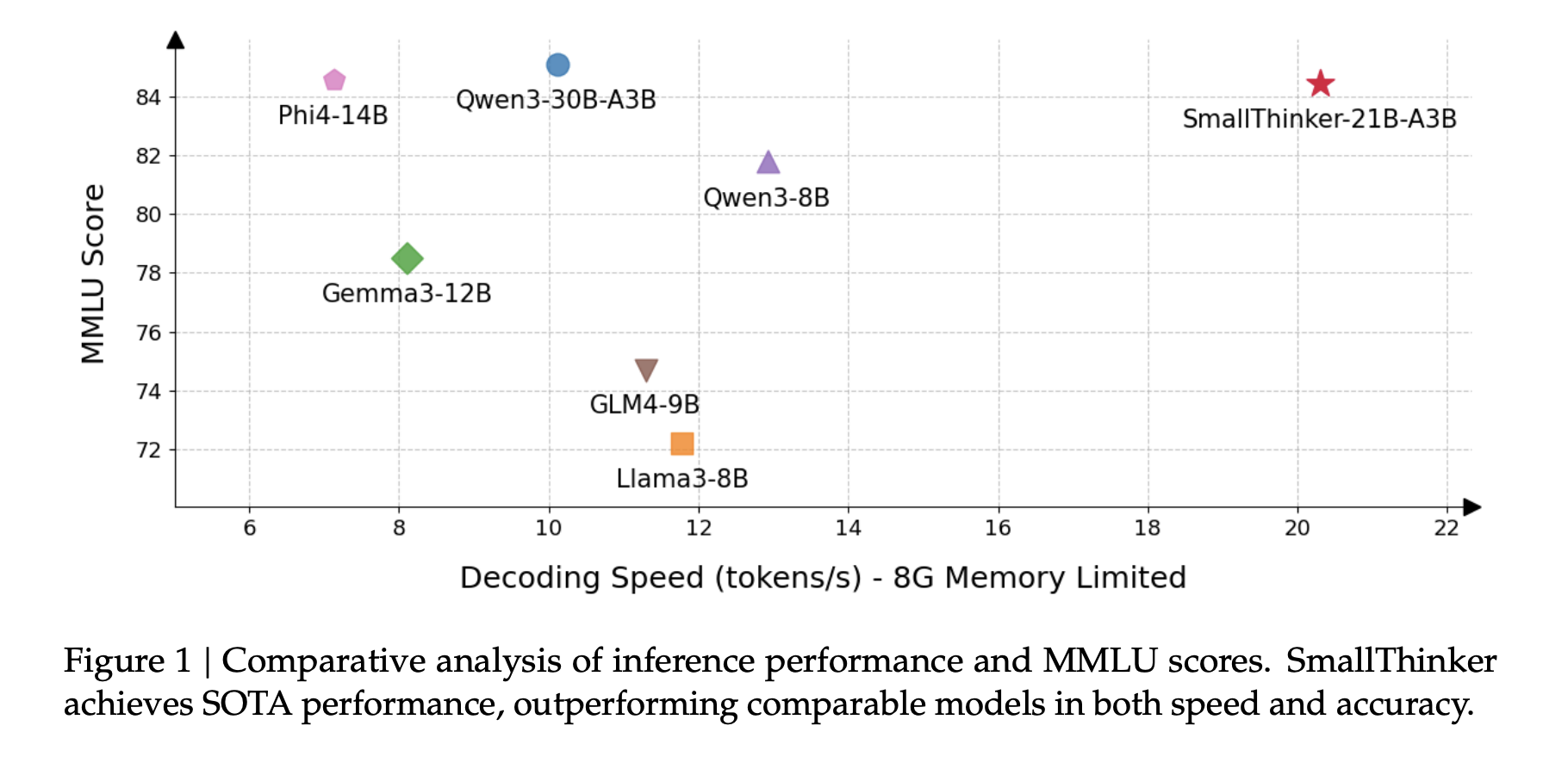
- SmallThinker-4B-A0.6B: With only 0.6B active parameters, this model achieves performance comparable to monolithic 3B parameter models on standard benchmarks
- SmallThinker-21B-A3B: The larger variant approaches the capabilities of 7B monolithic models while maintaining significantly lower memory and compute requirements
Most importantly, these models can run on:
- Mid-range laptops with 8GB RAM
- Recent smartphones with dedicated AI hardware
- Edge devices with limited computational resources
#Real-World Applications
The efficiency of SmallThinker enables several compelling use cases:
- Offline Personal Assistants: AI capabilities without cloud dependency or privacy concerns
- Document Analysis: Process sensitive documents locally without uploading to third-party services
- Embedded Systems: Smart home devices with advanced language understanding
- Mobile Applications: Rich AI features without draining battery or requiring constant connectivity
#Future Directions
The SmallThinker team is actively working on:
- Even Smaller Variants: Targeting ultra-low-power devices
- Multimodal Capabilities: Adding vision understanding while maintaining efficiency
- Domain-Specific Experts: Pre-trained experts for medical, legal, and technical domains
- Open Ecosystem: Tools for developers to customize and deploy SmallThinker models
#Conclusion
SmallThinker represents a significant step toward democratizing access to advanced AI capabilities. By designing for local constraints from the ground up rather than as an afterthought, these models deliver impressive performance without requiring expensive cloud infrastructure or compromising user privacy.
As AI continues to evolve, the SmallThinker approach demonstrates that "smaller and more efficient" doesn't necessarily mean "less capable" when architectural innovations are applied thoughtfully.